

 HDInsight 3.0 미리보기
HDInsight 3.0 미리보기
HDInsight 3.0 미리보기 Windows Azure HDInsight에서 Hadoop 2.2 클러스터를 생성해보도록 하겠습니다. Windows Azure 2월 업데이트 내용에서 HDInsight 3.0 미리보기 기능을 제공한다는 것을 알 수 있는데 간략히 살펴보도록 하겠습니다. HDInsight 3.0 미리보기의 Hadoop 버전은 아래 링크를 참고하십시오. http://www.windowsazure.com/en-us/documentation/articles/hdinsight-component-versioning/?fb=ko-kr 일단 먼저 저장소가 있어야 하므로 저장소를 생성해야 하는데 미국 동부, 미국 서부, 유럽 북부, 유럽 서부, 동남 아시아 지역이 가능합니다. 미리 저장소 계정을 생성해둡..
Windows with HDP 2.0 Hortonworks에서 HDP 2.0 for Windows를 발표했습니다. 자세한 정보를 아래에서 확인해보시기 바랍니다. http://hortonworks.com/blog/install-hadoop-windows-hortonworks-data-platform-2-0/?mkt_tok=3RkMMJWWfF9wsRoivqTAZKXonjHpfsX56O8lX6WylMI%2F0ER3fOvrPUfGjI4CSsdhI%2BSLDwEYGJlv6SgFT7TMMbFh1rgNUxc%3D HDP for Windows 는 Windows 서버 위에 Hadoop을 탑재한 플랫폼으로 Linux에서가 아닌 Windows 위에서 구동을 할 수 있는 내용이며 HDP 2.0 for Windows는 YARN..
 Windows Azure의 HDInsight 시작
Windows Azure의 HDInsight 시작
Windows Azure의 HDInsight 시작 HDInsight는 100% Apache Hadoop 솔루션을 Windows Azure에 구현한 Microsoft의 Hadoop 기반 서비스이며 HortonWorks의 HDP로 구성되어 있습니다. 또한 Hadoop on Windows도 제공하고 있습니다. l 신속한 배포 Windows Azure의 HDInsight를 사용하면 관리나 배포의 용이성을 간단하게 제공받을 수 있어 신속한 배포가 가능합니다. l 익숙한 도구를 통한 통찰력 Excel, PowerPivot을 통해 빅데이터의 쉬운 분석이 가능해 익숙한 도구를 통한 Insight가 가능합니다. l 다양한 프로그래밍 여러 언어를 통해 프로그래밍이 가능하도록 제공하고 있으며 LINQ to Hive를 제공하..
 MapReduce 2.0 (MRv2), YARN
MapReduce 2.0 (MRv2), YARN
MapReduce 2.0 (MRv2), YARN CDH, HDP 등에서도 YARN을 지원하고 있다는 것을 보실수 있는데 MapReduce의 경우 4000 노드까지 지원을 하게 되며 Name Node의 경우 가용성 적인 측면 등에서 제한적인 측면이 있는데 Hadoop 0.23 에서 오버홀하여 YARN 또는 MapReduce 2.0 (MRv2)를 지원합니다. MapReduce에서 JobTracker의 주요 기능을 여러 데몬으로 분리했는데, YARN의 전체적인 내용은 아래 그림을 참고하실 수 있습니다. 출처: http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html 구분 설명 구성 Resource Manager 마스터 서버 역할,..
 Hadoop Distribution
Hadoop Distribution
Hadoop Distribution Hadoop은 오픈 소스인데 Hadoop Ecosystem의 여러 오픈 소스 프로젝트를 묶어 배포하고 교육이나 컨설팅, 또는 추가 솔루션을 탑재하는 곳이 크게 외국 업체로 3 군데가 있습니다. 국내에도 업체들이 있습니다. 간략히 한번 살펴보겠습니다. l Coudera http://www.cloudera.com CDH(Coudera’s Distribution including Apache Hadoop)의 다이어그램은 아래 그림을 참고하실 수 있습니다. 출저: http://www.cloudera.com/content/cloudera/en/products-and-services/cdh.html 구체적인 오픈소스 프로젝트가 잘 안 보이는데 아래 링크에서 확인이 가능합니다. h..
빅 데이터 활용 기술 및 솔루션 빅 데이터 활용 기술 및 솔루션에 대해서 정리해보았습니다. 구분 기술 및 솔루션 인프라 - Hadoop 플랫폼 - In-Memory DBMS - In-Memory 컴퓨팅 (SAP HANA 등) - Appliance - 클라우드 컴퓨팅, Grid 컴퓨팅 수집 - Crawling, ETL Sqoop(RDB Import/Export) Chukwa(로그 데이터 수집) 저장 관리 분산 DBMS - RDBMS (Shared Nothing, Everything) RAC +ASM - NoSQL Column 기반(Hbase,Cassandra,HyperTable,SimpleDB) Key,Value 기반(Redis,Riak,Voldemort,WA Storage) Document 기반(Mong..
 데이터 과학자 – Data Scientist
데이터 과학자 – Data Scientist
데이터 과학자 – Data Scientist 며칠 전 전자 신문에 데이터 과학자에 대한 글이 1면에 나와서 정리해보았습니다. http://www.etnews.com/news/international/2750266_1496.html 엔지니어 입장에서 접근하다보니 Hive 로 SELECT t4, COUNT(*) FROM Table WHERE tx=’[ERROR]’ 로 결과를 표시하거나 EXCEL에서 연결해서 결과를 나오게 할 수는 있는데 나온 결과가 의미 있는거냐? 도움이 되는 거냐? 가치가 있는거냐? 나왔는데 그래서? 그 다음은? 1. 데이터 과학자 (Data Scientist) 가. 정의 - 고객의 행동이나 시장 주기 같은 구조화 되지 않은 대용량 데이터를 분석하여 새로운 가치를 창출하는 사람 나. 부각..
 D3
D3
D3 이전 글에서 잠시 언급한 D3 에 대한 내용을 한번 적용해보았습니다. 저번 글에 2 번이나 언급되어 있어서 수정했습니다. 오픈소스 빅데이터 요소 기술 D3는 시각화 언어로 javascript 라이브러리이며 HTML 5의 CSS 3, SVG와 동작되며 정말 다양하고 새로운 결과를 제공해줍니다. Data-Driven을 제공해주어 사용자 경험을 더 강화해주고 있습니다. 아래 링크를 통해 보다 더 자세한 정보를 확인 가능합니다. http://d3js.org/ https://github.com/mbostock/d3/wiki/Gallery https://github.com/mbostock/d3/wiki/Tutorials HTML 5의 SVG를 이용하여 D3로 바 차트를 구현해보겠습니다. jQuery를 사용해본..
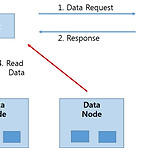 HDFS (Hadoop Distributed File System)
HDFS (Hadoop Distributed File System)
HDFS (Hadoop Distributed File System) I. HDFS(Hadoop Distributed File System) 개요 - Master/Slave 구조로 Master인 Name node가 파일의 메타(meta) 정보를 관리하고 실제 데이터는 여러 대의 Data node에 분산해서 저장하는 하둡 분산 파일 시스템 II. HDFS의 특징 및 읽기 및 쓰기 동작 가. HDFS의 특징 구분 특징 Data Block 파일을 블록단위로 쪼개서 여러 Data node에 나눠서 저장하고 각 파일의 기본 정보 및 각 블록들의 위치 정보를 Name node에서 관리 Replication 일부 Data node에 장애가 발생하더라도 데이터가 유실되는 것을 막기 위해 각 데이터 블록에 대해서 여러 개..
.NET SDK for Hadoop Microsoft .NET SDK for Hadoop 에 대한 내용이 올라왔습니다. 아래 링크를 참조하십시오. http://hadoopsdk.codeplex.com/ SDK는 아래 내용에 대한 부분을 포함하고 있습니다. l Map/Reduce l LINQ to Hive l WebHDFS Client 위의 내용을 NuGet 패키지로 제공하고 있습니다. 이중 LINQ to HIVE 에 대한 내용을 보시면 LINQ를 통해 Hadoop 데이터를 손쉽게 액세스 하는 것을 확인 할 수 있습니다. var db = new MyHiveDatabase("localhost", 10000); var q = from x in (from a in db.Actors select new { a.A..
- Total
- Today
- Yesterday
- SharePoint Online
- Power BI Update
- SQL Azure
- SharePoint Object Model
- Power BI Desktop 업데이트
- sql server 2012
- sharepoint
- Windows Phone 7
- 정홍주
- Power BI
- 페이지를 매긴 보고서
- redJu
- SharePoint 2013
- 클라우드
- Windows Azure Mobile Services
- Power BI Desktop Update
- Power BI Desktop
- Paginated Report
- 목표
- hongju
- Power BI 업데이트
- Windows Azure
- Power BI Copilot
- Visual Studio 2010
- 업데이트
- SharePoint 2010
- Cloud
- copilot
- Microsoft Fabric
- Windows Azure 업데이트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |